Lattice学习笔记06:SIS的困难度论证
Average Case Hardness(平均困难度)
Lattice问题最有趣的一点就在于困难度的论证。因为我们知道格中的一些问题是难的,比如说之前讨论的SVP、CVP、SIVP等等,所以基于这些问题构造的新的问题也是难的。反之,如果我们能够解决基于这些难题构造的新问题,那么我们也就可以解决这些难题本身。这一推理的过程,我们称之为reduction(规约)。
在讨论困难度的时候,最常见的一种方法就是讨论平均的困难度,即Average Case Hardness。
举个最简单的例子,在讨论像RSA一样依靠Factorization难度的系统的时候,我们会依靠我们的模组$ N $难以被factor这一难点来构造系统。比如说一个Modular Squaring的函数: $$ f_\mathbf{N}(\mathbf{x}) = \mathbf{x}^2 \text{ mod } \mathbf{N}:\mathbf{N} = p \cdot q $$ 这个函数就是计算一个数字$ \mathbf{x} $在模组中的平方,得到一个Quadratic Residue。这个函数也是Rabin的密码学系统的精髓,它的难度在于如果可以逆向计算$ f_\mathbf{N}(\mathbf{x}) $,我们也可以成功的factor $ \mathbf{N} $。
那么$ f_\mathbf{N}(\mathbf{x}) $这个函数到底有多难计算呢?我们需要看这个函数实例对应的$ \mathbf{N} $这个模组有多难被factor。因为它们之间的安全关系是一一对应的。Rabin给出的安全性证明为:在密码学定义上,只要大部分$ \mathbf{N} = p \cdot q $是难以被factor的,那么$ f_\mathbf{N} $这个函数也是难以被invert的。
理解这个定义很简单,假如我们随便拿到了一个$ f_\mathbf{N} $的实例,那么我们能够逆向它的可能性就基于我们随便拿到一个$ \mathbf{N} $可以factor它的可能性是相似的。这也就是说平均的看(在Average case上),只要我们大概率拿到的$ \mathbf{N} $是难的,那么$ f_\mathbf{N} $也是难的。
Ajtai的OWF(SIS)的平均困难度
同理可得,我们可以用这样的方法来分析之前提到的Ajtai OWF(即SIS)。
我们的OWF $ f_\mathbf{A}(\mathbf{x}) = \mathbf{Ax} \text{ mod }q $的构造其实和之前的Quadratic Residue的构造很相似,同时我们在之前也指出了想要逆向计算$ f_\mathbf{A} $的话,我们等于是需要求解Lattice $ \Lambda(\mathbf{A}) $中的SVP问题。所以$ \Lambda(\mathbf{A}) $的SVP难度与我们的OWF的安全性也是挂钩的。
这也就是说,如果我们随机的抽取$ \mathbf{A} $矩阵,并且给予它来构造OWF。只要保证大部分时候$ \Lambda(\mathbf{A}) $中的SVP是困难的,那么我们得到的$ f_\mathbf{A} $就是单向(OWF)并且collision resistant的。
Average Case Complexity(平均复杂度)
我们上面讨论的两个类似的问题,即Modular Squaring $ f_\mathbf{N} $和SIS OWF $ f_\mathbf{A} $,我们都可以把它们的难度规约到解决一些特殊问题的复杂度上。
比如在$ f_\mathbf{N} $的例子中,如果$ \mathbf{N} $难以factor,那么对应的算法复杂度也很高。但是什么样的数字难以被factor呢?
Factoring问题的定义是这样的:给定一个数字$ \mathbf{N} $,输出一组整数$ a, b > 1 $,并且满足$ \mathbf{N} = a \cdot b $。
使用很简单的数学尝试,我们就能发现,其实factoring的难度,和$ \mathbf{N} $这个数字的分布有很大的关系。如果$ \mathbf{N} $就是一个均匀分布的随机数字(uniformly random),那么: $$ Pr[\mathbf{N} = 2 \cdot \frac{\mathbf{N}}{2}] = \frac{1}{2} $$ 道理很简单,每两个相邻的数字中就一定有一个偶数,所以如果我们均匀的抽取随机数的话,factoring问题有一半的概率都是极其简单的。
为了避免这个问题,我们在挑选$ \mathbf{N} $的分布的时候需要格外的小心。如果我们挑选$ \mathbf{N} = p \cdot q $,并且选取$ p, q $为随机的质数,那么在这个新的$ \mathbf{N} $的分布下,我们相信factoring是困难的。所以说,整个factoring问题的平均复杂度,同时也是$ f_\mathbf{N} $的平均困难度定义,完全取决于我们如何挑选$ \mathbf{N} $的随机分布。如果是一个较好的分布,我们这个OWF从平均来看就是安全的,反之则不是。
这种精心挑选随机分布的方法对于$ f_\mathbf{N} $其实很有用,因为我们可以很直观的选出较好的随机分布出来(选择$ p, q $为随机大质数)。
现在我们来看Ajtai OWF。我们知道,只要$ \Lambda^\perp(\mathbf{A}) $的SVP问题困难,我们的SIS构造的OWF就是安全的。那么如果我们均匀的随机生成矩阵$ \mathbf{A} $,这个矩阵构成的格$ \Lambda, \Lambda^\perp $中的SVP问题到底难不难呢?换句话说,我们如何选择一个有利于我们SVP问题难度的随机分布$ \mathbf{A} $?这些问题,至少在现在,是很难有很好的答案的。
Worst Case Hardness(最坏情况困难度)
对于$ f_\mathbf{A} $,如果我们继续用平均困难度的方法,其实是很难得到一个很好的结果的。这个时候,我们可以换成另外一种思考角度,把这个平均问题进一步的规约成最坏情况问题。
这个reduction的方法其实不是很好理解,但是我们可以先来看一个假设。
我们之前的Ajtai OWF的定义方法,我们随机生成的$ \mathbf{A} $就对应了$ \Lambda(\mathbf{A}), \Lambda^\perp(\mathbf{A}) $这么两个Lattice,同理也就对应了最多两个不同的$ f_\mathbf{A} $实例,这样的话我们只能依靠平均困难度的方法来讨论$ f_\mathbf{A} $的安全性。
现在我们做一个新的假设:假如我们可以随机选择一个$ \mathbf{A} $,然后构成一个Lattice $ \Lambda $,但是有一种新的方法可以把这个Lattice映射到任意的$ f_\mathbf{A} $上去。这也就是说$ \Lambda(\mathbf{A}) $和$ f_\mathbf{A} $的一一对应关系已经没有了,一个Lattice可以变换组成任意的$ f_\mathbf{A} $的实例。
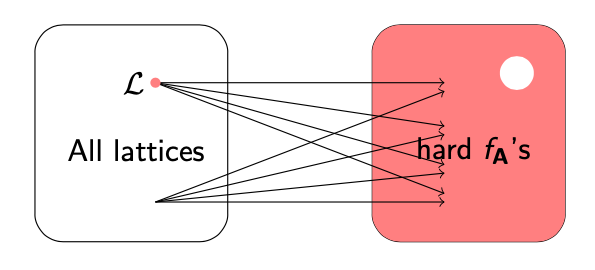
就像上图所示,我们一个Lattice $ \Lambda $可以对应多个OWF实例,甚至这个对应的关系也不是唯一的,是有重合的。在这种情况下,我们困难度的证明一下子就变了。
假设在所有的$ f_\mathbf{A} $中,大部分的实例(对应的SVP问题)都是难解的,但是如果我们有一个算法可以破解所有可能性中的一小部分实例(即图上的白色圆圈部分),那么我们就可以用这个算法来破解所有其他的$ \Lambda $实例中的SVP问题。原因也很简单,因为我们一个Lattice $ \Lambda $可以任意对应任意的$ f_\mathbf{A} $实例,所以就算是这个空间中”最难“破解的Lattice $ \Lambda $,也可以被映射到可以被破解的这一小部分$ f_\mathbf{A} $上,然后用已知的破解算法来破解出来。
这种类型的困难度论证被称为最坏情况困难度论证。也就是说,只要在整个取值空间中只要有任何(any)一个实例可以被破解,那么整个取值空间都可以被破解。
当年Ajtai提出SIS的时候,就做了这样的一个reduction,使用最坏情况困难度来证明SIS OWF的安全性。具体的出的结论是:只要有一部分(some)的Lattice $ \Lambda $中是难以计算SIVP的,那么基于随机取值的$ \mathbf{A} $定义的$ f_\mathbf{A} $是单向并且collision resistant的。
看到这里,我不禁有一点一头雾水。之前我们看到的SIS的构造都是从$ \mathbf{A} $构成的Lattice $ \Lambda $直接构造成固定的$ f_\mathbf{A} $实例,明明只有一种映射(或者两种,第二种就是$ \Lambda^\perp $),怎么能够实现上面说到的可以映射到任意的$ f_\mathbf{A} $实例的假设呢?
不要急,下面来研究一下如何实现这一假设。
Lattice模糊化(blurring)
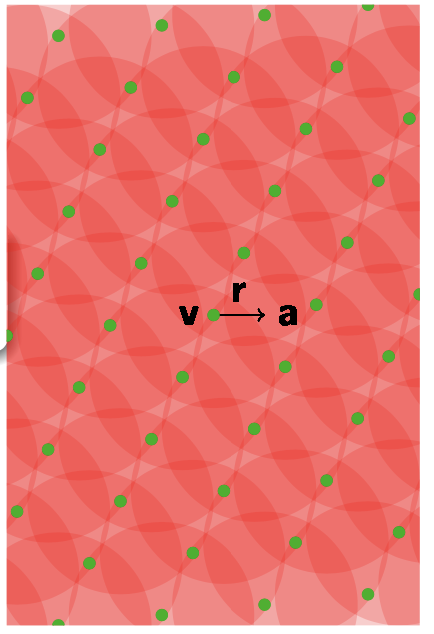
在之前的文章中讨论过可以把一个格$ \Lambda $的每一个点作为圆心,然后画一个圆(球体),并且让这个圆的半径逐渐变大。

当圆的半径等于这个Lattice的覆盖半径$ \mu $的时候,整个空间$ \mathbb{R}^n $都会被覆盖住。

当整个空间都被圆形覆盖住的时候,这个覆盖半径就是任意一个点可以距离格点最远的距离。现在我们假设这些圆当作一个以格点为中心的随机误差的分布$ \mathcal{X} $。
这个时候,在$ \mathbb{R}^n $空间中的任意一个点$ \mathbf{a} $都可以被拆分成如下的形式: $$ \mathbf{a = v + r} $$ 这里的$ \mathbf{v} $就是Lattice $ \Lambda $中的一个格点,$ \mathbf{r} $则是误差分布中的一个随机误差向量。如果我们现在随机的选择一个格点,再从误差分布中随机的选择一个误差向量,把它们相加起来的话,就可以近似地得到一个$ \mathbb{R}^n $空间中的随机向量。
我们观察可以发现,图上的圆的半径仅仅是覆盖半径,整个空间中有很多部分重合的地方。这个时候我们用这种方法生成的随机向量的分布其实并不是均匀的,而是会偏向这些重合的地方。
这个时候,我们需要继续增加半径的大小,使得这个分布变得越来越近似于平均分布。
 $$
\lvert \lvert \mathbf{r} \rvert \rvert \le (\log{n}) \cdot \sqrt{n} \cdot \lambda_n/2 \approx \sqrt{n} \cdot \lambda_n
$$
当我们的误差分布半径达到如上所示的值的时候,如果我们只看这个格的基础空间(即Determinant组成的parallelpiped,或者$ \mathbb{R}^n/\Lambda $的模组空间),我们可以把这个空间中的错误分布看作平均分布。
$$
\lvert \lvert \mathbf{r} \rvert \rvert \le (\log{n}) \cdot \sqrt{n} \cdot \lambda_n/2 \approx \sqrt{n} \cdot \lambda_n
$$
当我们的误差分布半径达到如上所示的值的时候,如果我们只看这个格的基础空间(即Determinant组成的parallelpiped,或者$ \mathbb{R}^n/\Lambda $的模组空间),我们可以把这个空间中的错误分布看作平均分布。
这个时候,我们已经把这个格足够的模糊化了。当我们得到一个模糊化之后的Lattice之后,就可以来完成Ajtai OWF的安全性论证了。
Ajtai OWF的安全性论证尝试
最后,我们来尝试使用最坏情况复杂度的规约来证明Ajtai OWF的安全性(即单向和collision resistant)。
上一步我们成功的得到了一个模糊化之后的Lattice $ \Lambda $,现在我们来看看这个格是否满足我们刚刚看到的假设,即$ \Lambda $可以映射到任意的$ f_\mathbf{A} $上。
首先,我们可以用上面提到的方法,先随机的生成一个$ \Lambda $中的格点$ \mathbf{v}_i $。然后我们从随机噪音分布中生成一个噪音向量$ \mathbf{r}_i $,并且根据我们模糊化的结果,$ \lvert \lvert \mathbf{r} \rvert \rvert \le \sqrt{n} \cdot \lambda_n $。 $$ \mathbf{a}_i = \mathbf{v}_i + \mathbf{r}_i $$ 我们把这两个随机的向量组合起来,变成我们的目标向量$ \mathbf{a}_i $。根据模糊化的结果,我们知道$ \mathbf{a}_i $的随机分布是近似平均分布的。
这个时候,我们连续的取得$ m $个类似的向量,这里$ q = n^{O(1)}, m = O(n \log{q}) = O(n \log{n}) $: $$ \mathbf{A} = [\mathbf{a}_1, \dots, \mathbf{a}_m] \in \mathbb{R}^{n \times m}_q $$ 因为我们是拼接了$ m $个类似的随机向量得到矩阵$ \mathbf{A} $的,所以这个矩阵也可以被看作是随机分布的。
得到了$ \mathbf{A} $之后,我们使用这个矩阵来构造一个Ajtai OWF的实例$ f_\mathbf{A} $。这个时候,因为从$ \mathbf{A} $根本看不出来我们原本的Lattice是什么结构的,对于一个adversary来说,这个$ f_\mathbf{A} $就是一个平均情况的,可能是任何Lattice形成的一个Ajtai OWF实例。这个时候,就算我们一开始使用的是空间中“最难的”一个Lattice生成的随机向量,因为adversary并不知道这一回事,所以他只会觉得他在求解一个平均难度的问题。
听起来感觉有些烧脑,但是这就是最坏情况到平均情况的规约的精髓了!我们把一个最坏情况的Lattice“伪装”成了一个平均情况的实例。这个时候,如果adversary拥有一个算法可以破解一小部分的$ f_\mathbf{A} $的化,那么它就有一定的几率可以破解我们创造的这个实例。
如果adversary可以成功的破解这个$ f_\mathbf{A} $实例的话,那么就代表我们找到了一个短向量$ \mathbf{z} \in {-1, 0, 1}^m $并且满足: $$ \sum (\mathbf{v}_i + \mathbf{r}_i)\mathbf{z}_i = \sum \mathbf{a}_i \mathbf{z}_i = 0 $$ 我们把这个等式变换一下,就可以得到如下的形式: $$ \sum \mathbf{v}_i \mathbf{z}_i = -\sum \mathbf{r}_i \mathbf{z}_i $$ 观察可以发现,等式的左侧我们可以得到一个格点,而右侧我们可以得到一个相对来说较短的向量(并不是格点)。因为$ \mathbf{r} $向量长度的上限和$ \mathbf{z} $向量是个短向量的原因,我们可以约束右侧的向量: $$ \lvert \lvert \sum \mathbf{r}_i \mathbf{z}_i \rvert \rvert \approx \sqrt{m} \cdot \max \lvert \lvert \mathbf{r}_i \rvert \rvert \approx n \cdot \lambda_n $$ 虽然右侧的向量并不在格点上,但是我们发现这个向量相对来说还是比较短的。因为左侧的在$ \Lambda $格中的向量的值等于右侧的向量的值,这就代表说左侧的格点向量也是很短的。这样一来,我们就等于间接的解决了$ \Lambda $中的短向量了。
回到我们一开始的定义,如果找到了短向量(近似SIVP)问题,那么我们就可以成功的破解SIS OWF。根据我们最坏情况困难度的规约,只要所有的随机格中有任何一部分(some)Lattice可以被破解,那么我们就可以破解任何平均情况的Lattice,找到它们的短向量。综上所述,因为我们知道SIVP是困难的问题,所以这些事情都不可能,所以SIS OWF也是安全的了。
QED
写到这里,其实多少还是对于这个reduction有点模糊,并不是完全的掌握。想了想还有一个比较好的理解方法:如果只依靠平均情况hardness的话,那么代表$ f_\mathbf{A} $在大部分情况下都是安全的, 但是不排除有踩雷的情况(生成了比较差的弱实例)。这就等于说是我们有一块地,可以确保80%的地方都是安全的,但是剩下的20%说不定有地雷,有窟窿,但是我们不知道,说不定那天就踩到了,这是令人感到很不安心的。
但是如果我们依靠最坏情况的hardness reduction的话,那么代表在$ \mathbf{A} $的随机取值空间中,可以被破解的实例几乎没有(negligible),所以整体$ f_\mathbf{A} $都是安全的。因为只要有任何一部分(non-negligible)的实例可以被破解,那么基本上整个$ f_\mathbf{A} $都会随之被攻破。这就好比是告诉我们有一块地,可以确保几乎没有任何地雷和窟窿(比如$ <0.1% $,negligible)。
Credits
The contents of this post is summarized from Prof. Daniele Micciancio’s lecture at Simon’s Institute Lattice Bootcamp.