Lattice学习笔记01:格的简介
Lattice的历史
Lattice(格)在很早以前就被各大数学家研究了一遍。代表人物有Lagrange,Gauss和Minkowski等等。最近的几十年内,Lattice在密码学、通讯、密码分析上有了很大的应用价值,是非常火的一个领域。
近代Lattice时间线:
- 1982:LLL basis reduction theorem
- 使用Lattice来做Cryptanalysis
- 1996:Ajtai-Dwork
- 第一次把Lattice中Average-case与Worst-case的复杂度问题关联起来
- 提出了使用Lattice构造的One-way Function与CRHF(Collision Resistant Hash Function)
- 2002:找到了Average-case/worst-case复杂度之间的关系,基于Lattice的协议变得更加高效
- 2005:Regev提出了LWE,并且发现其量子抵抗性
- 提出PKE,IBE,ABE,FHE等等的可能性
Lattice是什么
Lattice可以被想象成是一个空间中很多有规律分布的、离散的点。
$ n $维空间中最简单的Lattice就是Integer Lattice(整数格)。整数格中最简单的就是基于笛卡尔坐标系的$ \hat{i}, \hat{j}, … $等基向量组成的空间。
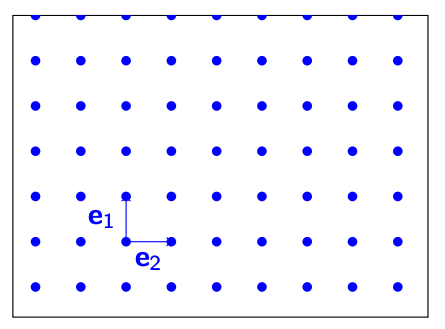 $$
\Lambda = \mathbb{Z}^n$$
我们可以对此Lattice进行任意的线性变换(Linear Transformation)$ B $,然后可以得到新的Lattice。
$$
\Lambda = \mathbb{Z}^n$$
我们可以对此Lattice进行任意的线性变换(Linear Transformation)$ B $,然后可以得到新的Lattice。
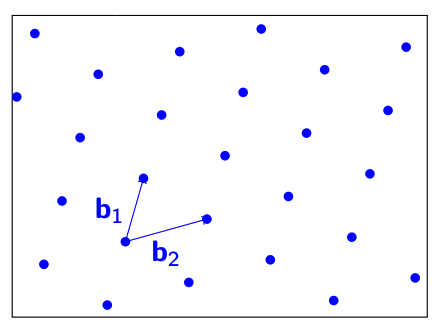 $$
\Lambda = B \cdot \mathbb{Z}^n : B \in \mathbb{R}^{d \times n}$$
$$
\Lambda = B \cdot \mathbb{Z}^n : B \in \mathbb{R}^{d \times n}$$
Lattice与Bases(格与基)
更好的描述一个格的方法是使用基向量。
我们假设一个格拥有基向量$ \mathbf{b}_1, \dots, \mathbf{b}_n $。那么这个Lattice就是它的基向量的任意线性组合的集合,我们也可以把所有基向量组合成矩阵$ \mathbf{B} $来表示。
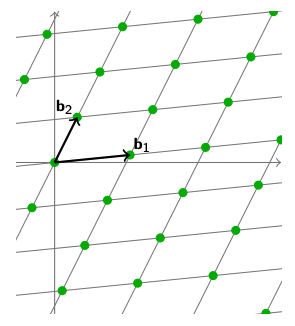 $$
\mathcal{L} = \sum^n_{i=1} \mathbf{b}_i \cdot \mathbb{Z} = {\mathbf{Bx}: \mathbf{x} \in \mathbb{Z}^n}$$
同理可得,我们可以用线性代数中学到的基变更(Change of basis)给这个Lattice找到一组新的基$ \mathbf{C} $。
$$
\mathcal{L} = \sum^n_{i=1} \mathbf{b}_i \cdot \mathbb{Z} = {\mathbf{Bx}: \mathbf{x} \in \mathbb{Z}^n}$$
同理可得,我们可以用线性代数中学到的基变更(Change of basis)给这个Lattice找到一组新的基$ \mathbf{C} $。
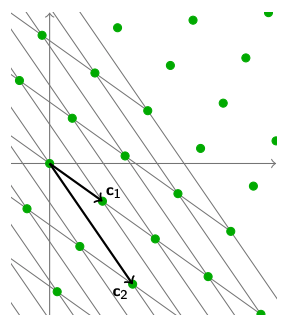 $$
\mathcal{L} = \sum^n_{i=1} \mathbf{c}_i \cdot \mathbb{Z}$$
如果系统性的定义一下Lattice的话,那么我们可以说Lattice是$ \mathbb{R}^n $这个空间中的一个离散的、具有加法运算的子群(A discrete additive subgroup)。
$$
\mathcal{L} = \sum^n_{i=1} \mathbf{c}_i \cdot \mathbb{Z}$$
如果系统性的定义一下Lattice的话,那么我们可以说Lattice是$ \mathbb{R}^n $这个空间中的一个离散的、具有加法运算的子群(A discrete additive subgroup)。
Lattice的基本属性
我们知道,在一个线性空间里面,一个空间$ V $的Determinant(行列式)$ det(V) $代表了这个空间所有的基向量$ b_i $所组成的几何体的体积。在二维空间里,两个基向量$ b_1, b_2 $组成的平行四边形的面积就是这个空间的Determinant。
同理可得,一个Lattice的Determinant也是一样的——对应的基向量所组成的Parallelepiped的体积。
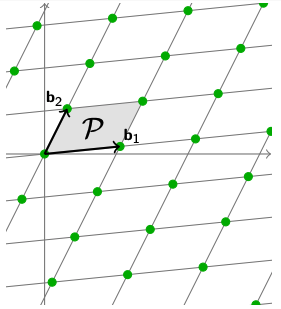 $$
det(\mathcal{L}) = \sum_i \mathbf{b}_i \cdot [0, 1) = vol(\mathcal{P}(\mathbf{B}))$$
同理,我们换了一组基向量,也可以计算它的Determinant。
$$
det(\mathcal{L}) = \sum_i \mathbf{b}_i \cdot [0, 1) = vol(\mathcal{P}(\mathbf{B}))$$
同理,我们换了一组基向量,也可以计算它的Determinant。
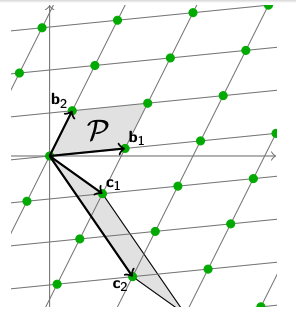
值得注意的是,无论我们怎么更换基向量,Determinant的大小,即基向量组成的多面体的体积是相同的。给定任意的一组基向量,我们都可以有效的找到这个Lattice空间的Determinant。
Lattice的密度
我们可以用一个Lattice的Determinant来衡量这个格的点阵分布的密度。
首先,我们把上一部分基向量组成的多面体的中心挪到原点上来。这样,空间$ \mathcal{P} $仍然保持相同的体积。 $$ \mathcal{P} = \sum_i \mathbf{b}_i \cdot [-1/2, 1/2)\ vol(\mathcal{P(\mathbf{B})}) = det(\mathcal{L})$$ 随后,我们可以把这个多面体复制多份,然后平移到每一个Lattice中的点上。这样我们就会得到很多份$ \mathcal{P} $,并且这些多面体可以平分整个多维空间$ \mathbb{R}^n $。
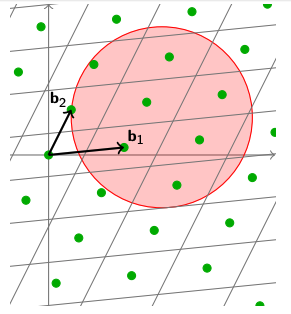
此时,我们如果在这个空间中任意的画一个球体(多维空间即超球体),然后可以数数看这个球体中覆盖了多少Lattice里的点。点的数量平均于球体的体积,就是这个格的密度了。 $$ \text{For all sufficiently large } S \subseteq \mathbb{R}^n:\ \lvert S \ \cap \ \mathcal{L} \rvert \approx vol(S)/det(\mathcal{L})$$ 这个概念理解起来也非常简单。我们的球体中有多少个Lattice的点,其实大概和球体的体积中有多少个$ det(\mathcal{L}) $的多面体,这两个比例大致相同。
最短距离
我们一般用$ \lambda_1 $来定义整个格中点与点之间最短的距离。一般为了方便理解,我们就把其中的一个点设置成坐标轴0点,然后$ \lambda_1 $就变成了距离0点距离最近的格点。 $$ \begin{align*} \lambda_1 &= \min_{x,y \in \mathcal{L}, x \ne y} \lvert \lvert x - y \rvert \rvert\ &= \min_{x \in \mathcal{L}, x \ne 0} \lvert \lvert x \rvert \rvert \end{align*}$$ 同理可得,我们也可以定义距离第二近的点距离$ \lambda_2 $,第三近的$ \lambda_3 $,一直到第$ n $近的$ \lambda_n $。
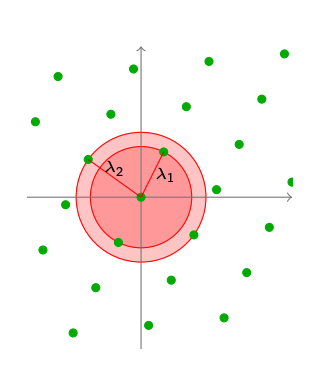
这些$ \lambda_i $之间需要遵守一个最简单的规律: $$ \lambda_1 \le \lambda_2 \le \dots \le \lambda_n$$ 一个特殊的例子就是笛卡尔坐标系下的整数格$ \mathbb{Z}^n $,因为所有的基向量全部都长度相等,并且相互垂直,所以$ \lambda_1 = \lambda_2 = \dots = \lambda_n = 1 $。
距离函数(Distance Function)与覆盖半径(Covering Radius)
给定任意一个点$ \mathbf{t} $(这个点不需要在Lattice上),我们可以定义距离函数$ \mu(\mathbf{t}, \mathcal{L}) $为这个点到附近的Lattice点的最短距离。
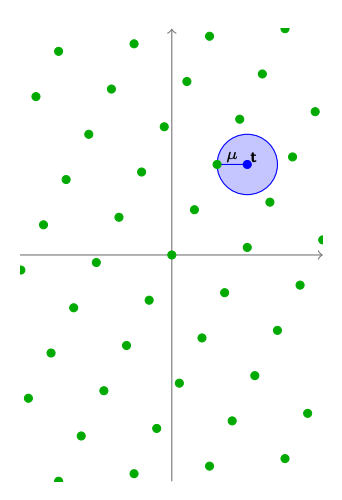 $$
\mu(\mathbf{t}, \mathcal{L}) = \min_{\mathbf{x} \in \mathcal{L}} \lvert \lvert \mathbf{t} - \mathbf{x} \rvert \rvert$$
同理可得,我们也可以左右移动$ \mathbf{t} $的位置,然后就可以找到在这个Lattice中可以得到的最大的$ \mu $。我们一般称这个最大值叫覆盖半径(Covering Radius)。
$$
\mu(\mathbf{t}, \mathcal{L}) = \min_{\mathbf{x} \in \mathcal{L}} \lvert \lvert \mathbf{t} - \mathbf{x} \rvert \rvert$$
同理可得,我们也可以左右移动$ \mathbf{t} $的位置,然后就可以找到在这个Lattice中可以得到的最大的$ \mu $。我们一般称这个最大值叫覆盖半径(Covering Radius)。
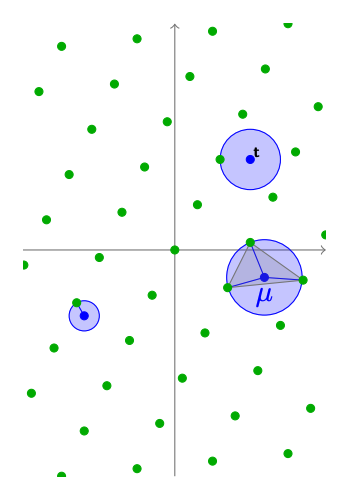 $$
\mu(\mathcal{L}) = \max_{\mathbf{t} \in span(\mathcal{L})} \mu(\mathbf{t}, \mathcal{L})$$
为什么称这个最远距离为覆盖半径呢,其实很简单。我们可以假设在这个Lattice中,以每个格点为圆心画很多歌圆。
$$
\mu(\mathcal{L}) = \max_{\mathbf{t} \in span(\mathcal{L})} \mu(\mathbf{t}, \mathcal{L})$$
为什么称这个最远距离为覆盖半径呢,其实很简单。我们可以假设在这个Lattice中,以每个格点为圆心画很多歌圆。
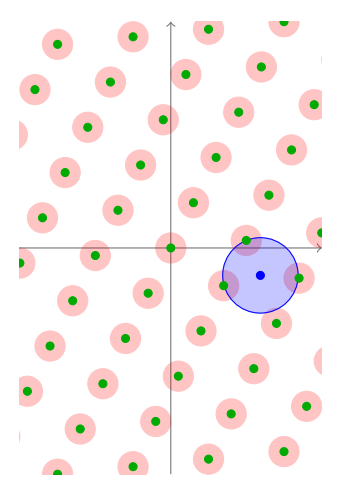
如果逐渐把圆的半径扩大的话, 那么所有的圆就会逐渐开始覆盖整个$ \mathbb{R}^n $空间。
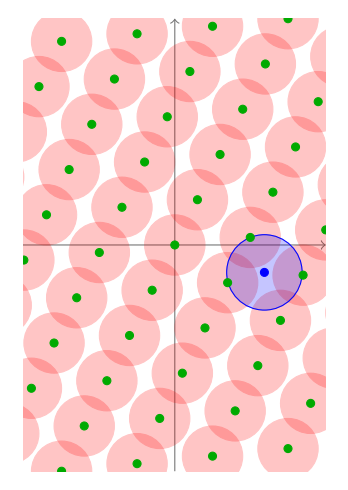
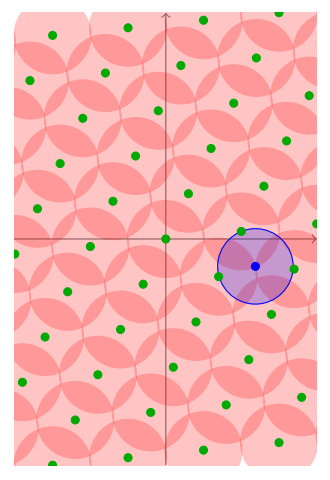
直到所有的圆正好完美的覆盖了所有的空间的时候,这个时候的半径,就是我们之前得到的$ \mu $了。这就是覆盖半径这一名字的由来。
Lattice的Smoothing
如果我们把上面的覆盖圆的概念稍微转换一下,假设我们不是在每个格点上叠加一个圆形,而是叠加一个圆形范围内取值的随机噪音,那么当圆的半径达到覆盖半径之后,这个Lattice本身就和背后的连续空间$ \mathbb{R}^n $合二为一了。
但是如果就只是在覆盖半径上的话,可以在图上发现,噪音覆盖的分布非常的不平均,因为格点之间相互的位置的问题。这也就是说,叠加了噪音之后,最后得到在$ \mathbb{R}^n $上的取值分布也不平均。
如果想让取值分布更加平均的话,我们就需要更多的Smooth(平滑化?)这个Lattice,即继续扩大圆的半径。理论上当半径接近于无限大的时候,我们得到的分布是最完美、最平均的。但是当圆无限大了之后,这个构造就没有太多实际操作的意义了。

所以一般来说,我们都会给这个Smoothing的半径一个最大上限。这个最大上限是由这个Lattice中距离最大的最短向量$ \lambda_n $来决定的。因为当我们的半径大于了这个最短向量之后,那么这个圆就会覆盖太多的点(因为最短距离决定了点到点之间的距离),然后这个构造就失去了意义。 $$ \lvert \lvert \mathbf{r} \rvert \rvert \le log(n) \cdot \sqrt{n} \lambda_n$$ 对于Lattice的Smoothing一直是一个比较火的研究领域。现在最常见的方法是在这个覆盖圆中叠加高斯分布的噪音$ \mathbf{r} $(Gaussian Noise)。 $$ \lvert r_i \rvert \approx \eta_\epsilon \le log(n)\lambda_n$$ 等式中的$ \eta_\epsilon $即这个Lattice的Smoothing参数。
Minkowski凸集定理(Convex body theorem)
对于Lattice,Minkowski给出了几个比较有意思的定理。第一个定理是用于寻找一个格点周围最近的其他格点的,即凸集定理。
假如说我们拥有一个对称的凸集$ C \subset \mathbb{R}^n $,我们暂可以理解为是一个多维空间的一部分(一个多维物体)。为了方便理解,我们把这个凸集放在0坐标点上。
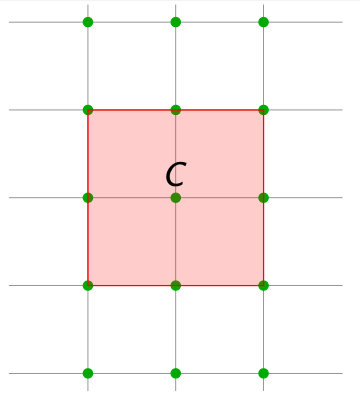
如果这个多维物体的体积$ vol(C) > 2^n $,那么这个集合中一定会包括另一个非0的格点。
在整数格$ \mathbb{Z}^n $中非常好理解,因为以原点出发到所有下一个点这段距离构成的空间,恰好就是$ 2^n $,所以说任何凸集(集合的表面不能有凹陷)只要体积大于$ 2^n $,那就一定会溢出这段空间,进而覆盖某个非0的格点。通过Pigeonhole Principle(鸽子洞原理)就可以很生动的理解了。
接下来,如果我们换成一个不规则的Lattice,即在原有的$ \mathbb{Z}^n $上叠加线性变换,这个定理还是成立的。
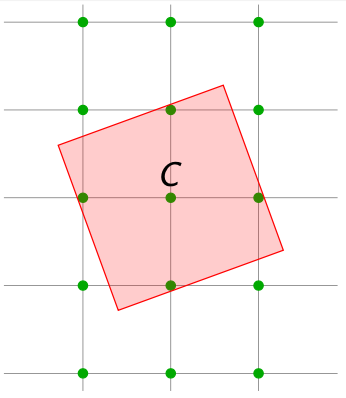
我们叠加线性变换$ \mathbf{B} $得到了新的Lattice $ \mathcal{L} = \mathbf{B} \mathbb{Z}^n $,然后我们计算出在这个Lattice下的Determinant构成的$ n $维空间,如果压缩成一个立方体之后的边长$ r = det(\mathcal{L})^{1/n} $。
我们定义我们的凸集$ C = \mathbf{B}^{-1}[-r, r]^n $,即一个边长为$ 2r $的$ n $维立方体叠加了反向的线性变换$ \mathbf{B} $。这个立方体的体积为: $$ vol(C) = det(\mathbf{B})^{-1}(2r)^n = 2^n$$ 因为$ C $的体积大于等于$ 2^n $,基于Minkowski定理,集合$ C $中一定包含一个非0的$ \mathbb{Z}^n $中的格点$ \mathbf{x} \in \mathbb{Z}^n \setminus {0} $。同理可得,当我们对于$ C $叠加了线性变换$ B $之后,$ \mathbf{B}C = [-r, r]^n $。这个变换后的$ \mathbf{B}C $的体积也大于等于$ 2^n $,所以肯定会包含新的空间$ \mathcal{L} $中的格点$ \mathbf{Bx} $。
Minkowski定理最重要的用处就是给出一个Lattice中最短向量的一个上限值。 $$ \lambda_1(\mathcal{L}) \le \sqrt{n}r = \sqrt{n} \cdot det(\mathcal{L})^{1/n}$$ 理解这个上限其实很简单,我们如果把这个Lattice的Determinant对应的空间压缩成一个立方体,那么这个立方体的对角线长度就是$ \sqrt{n}r $。因为对角线的另一头就是下一个格点了(但不一定是最近的格点),所以$ \lambda_1 $肯定要小于等于这个对角线的长度。
Minkowski第二定理
如果说Minkowski第一定理给出了对于最短向量$ \lambda_1 $的一个上限的话,第二定理给出了对于其他最短向量$ \lambda_i $的一个取值上限。 $$ \lambda_1(\mathcal{L}) \le \left( \prod_i \lambda_i(\mathcal{L}) \right)^{1/n} \le \sqrt{n} \cdot det(\mathcal{L})^{1/n}$$ 第二定理指出,全部$ n $个最短向量的几何平均数,一定会小于等于我们之前给出的$ \sqrt{n}r $这个对角线的长度。这个其实就是对于上面我们说的把一个任意的Determinant对应的空间压缩成一个等边长的立方体的话,对角线就是$ \sqrt{n}r $这么长。然而现实中一个任意Lattice的Determinant空间是一个不规则的Parallelepiped,所以边长肯定各不相同。但是因为体积是一样的,所以我们用几何平均数的方法就可以很好的约束这个Parallelpiped每个边的长度。
Credits
The contents of this post is summarized from Prof. Daniele Micciancio’s lecture at Simon’s Institute Lattice Bootcamp.